Can event management help foster a curiosity for innovative possibilities to make application performance better? Blue-sky thinkers may not want to deal with the myriad of details on how to manage the events being generated operationally, but could learn something from this exercise.
Consider the major system failures in your organization over the last 12 to 18 months. What if you had a system or process in place to capture those failures and mitigate them from a proactive standpoint preventing them from reoccurring? How much better off would you be if you could avoid the proverbial “Groundhog Day” with system outages? The argument that system monitoring is just a nice to have, and not really a core requirement for operational readiness, dissipates quickly when a critical application goes down with no warning.
Starting with the Event management and Incident management processes may seem like a reactive approach when implementing an Application Performance Management (APM) solution, but is it really? If “Rome is burning”, wouldn’t the most prudent action be to extinguish the fire, then come up with a proactive approach for prevention? Managing the operational noise can calm the environment allowing you to focus on APM strategy more effectively.
Asking the right questions during a post-mortem review will help generate dialog, outlining options for alerting and prevention. This will direct your thinking towards a new horizon of continual improvement that will help galvanize proactive monitoring as an operational requirement.
Here are three questions that build on each other as you work to mature your solution:
1. Did we alert on it when it went down, or did the user community call us?
2. Can we get a proactive alert on it before it goes down, (e.g. dual power supply failure in server)?
3. Can we trend on the event creating a predictive alert before it is escalated, (e.g. disk space utilization to trigger a minor@90%, major@95%, critical@98%)?
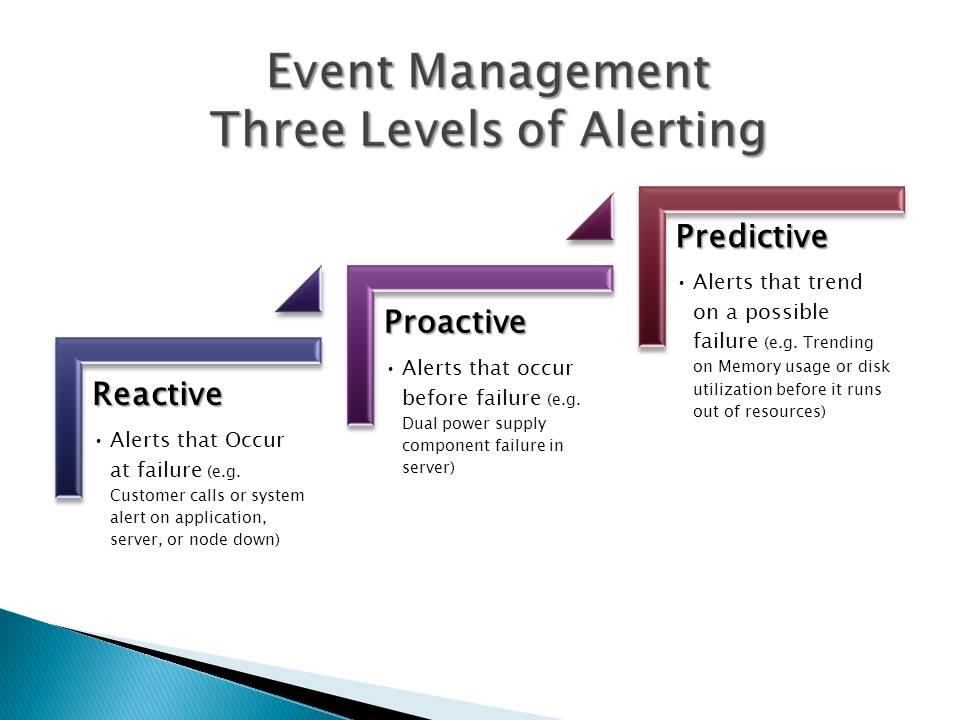
The preceding questions are directly related to the following categories respectively: Reactive, Proactive, and Predictive.
Reactive – Alerts that Occur at Failure
Multiple events can occur before a system failure; eventually an alert will come in notifying you that an application is down. This will come from either the users calling the Service Desk to report an issue or it will be system generated corresponding with an application failure.
Proactive – Alerts that Occur Before Failure
These alerts will most likely come from proactive monitoring to tell you there are component failures that need attention but have not yet affected overall application availability, (e.g. dual power supply failure in server).
Predictive – Alerts that Trend on a Possible Failure
These alerts are usually set up in parallel with trending reports that will help predict subtle changes in the environment, (e.g. trending on memory usage or disk utilization before running out of resources).
Conclusion
Once you build awareness in the organization that you have a bird’s eye view of the technical landscape and have the ability to monitor the ecosystem of each application (as an ecologist), people become more meticulous when introducing new elements into the environment. They know that you are watching, taking samples, and trending on the overall health and stability leaving you free to focus on the strategic side of APM without distraction.
You can contact Larry on LinkedIn
Related Links:
For a high-level view of a much broader technology space refer to the slide show on BrightTALK.com which describes the “The Anatomy of APM - webcast” in more context.
For more information on the critical success factors in APM adoption and how this centers around the End-User-Experience (EUE), read The Anatomy of APM and the corresponding blog APM’s DNA – Event to Incident Flow.
The Latest
Broad proliferation of cloud infrastructure combined with continued support for remote workers is driving increased complexity and visibility challenges for network operations teams, according to new research conducted by Dimensional Research and sponsored by Broadcom ...
New research from ServiceNow and ThoughtLab reveals that less than 30% of banks feel their transformation efforts are meeting evolving customer digital needs. Additionally, 52% say they must revamp their strategy to counter competition from outside the sector. Adapting to these challenges isn't just about staying competitive — it's about staying in business ...
Leaders in the financial services sector are bullish on AI, with 95% of business and IT decision makers saying that AI is a top C-Suite priority, and 96% of respondents believing it provides their business a competitive advantage, according to Riverbed's Global AI and Digital Experience Survey ...
SLOs have long been a staple for DevOps teams to monitor the health of their applications and infrastructure ... Now, as digital trends have shifted, more and more teams are looking to adapt this model for the mobile environment. This, however, is not without its challenges ...
Modernizing IT infrastructure has become essential for organizations striving to remain competitive. This modernization extends beyond merely upgrading hardware or software; it involves strategically leveraging new technologies like AI and cloud computing to enhance operational efficiency, increase data accessibility, and improve the end-user experience ...
AI sure grew fast in popularity, but are AI apps any good? ... If companies are going to keep integrating AI applications into their tech stack at the rate they are, then they need to be aware of AI's limitations. More importantly, they need to evolve their testing regiment ...
If you were lucky, you found out about the massive CrowdStrike/Microsoft outage last July by reading about it over coffee. Those less fortunate were awoken hours earlier by frantic calls from work ... Whether you were directly affected or not, there's an important lesson: all organizations should be conducting in-depth reviews of testing and change management ...
In MEAN TIME TO INSIGHT Episode 11, Shamus McGillicuddy, VP of Research, Network Infrastructure and Operations, at EMA discusses Secure Access Service Edge (SASE) ...
On average, only 48% of digital initiatives enterprise-wide meet or exceed their business outcome targets according to Gartner's annual global survey of CIOs and technology executives ...
Artificial intelligence (AI) is rapidly reshaping industries around the world. From optimizing business processes to unlocking new levels of innovation, AI is a critical driver of success for modern enterprises. As a result, business leaders — from DevOps engineers to CTOs — are under pressure to incorporate AI into their workflows to stay competitive. But the question isn't whether AI should be adopted — it's how ...




