

The global IT skills shortage will persist, and perhaps worsen, over the next few years, carrying a collective price tag of more than $5 trillion. Organizations must search for ways to streamline their IT service management (ITSM) workflows in addition to, or even apart from, hiring more staff. Those who don't find alternative methods of ITSM efficiency will be left behind by their competitors ...
Embedding greater levels of deep learning into enterprise systems demands these deep-learning solutions to be "explainable," conveying to business users why it predicted what it predicted. This "explainability" needs to be communicated in an easy-to-understand and transparent manner to gain the comfort and confidence of users, building trust in the teams using these solutions and driving the adoption of a more responsible approach to development ...
Modern people can't spend a day without smartphones, and businesses have understood this very well! Mobile apps have become an effective channel for reaching customers. However, their distributed nature and delivery networks may cause performance problems ... Performance engineering can be a solution.

Industry experts offer predictions on how Cloud, FinOps and related technologies will evolve and impact business in 2025. Part 3 covers FinOps ...
Industry experts offer predictions on how Cloud, FinOps and related technologies will evolve and impact business in 2025. Part 2 covers repatriation and more ...
Industry experts offer predictions on how Cloud, FinOps and related technologies will evolve and impact business in 2025 ...
Industry experts offer predictions on how NetOps, Network Performance Management, Network Observability and related technologies will evolve and impact business in 2025 ...
In APMdigest's 2025 Predictions Series, industry experts offer predictions on how Observability and related technologies will evolve and impact business in 2025. Part 6 covers cloud, the edge and IT outages ...
In APMdigest's 2025 Predictions Series, industry experts offer predictions on how Observability and related technologies will evolve and impact business in 2025. Part 5 covers user experience, Digital Experience Management (DEM) and the hybrid workforce ...
In APMdigest's 2025 Predictions Series, industry experts offer predictions on how Observability and related technologies will evolve and impact business in 2025. Part 4 covers logs and Observability data ...
In APMdigest's 2025 Predictions Series, industry experts offer predictions on how Observability and related technologies will evolve and impact business in 2025. Part 3 covers OpenTelemetry, DevOps and more ...
In APMdigest's 2025 Predictions Series, industry experts offer predictions on how Observability and related technologies will evolve and impact business in 2025. Part 2 covers AI's impact on Observability, including AI Observability, AI-Powered Observability and AIOps ...
The Holiday Season means it is time for APMdigest's annual list of predictions, covering IT performance topics. Industry experts — from analysts and consultants to the top vendors — offer thoughtful, insightful, and often controversial predictions on how Observability, APM, AIOps and related technologies will evolve and impact business in 2025 ...
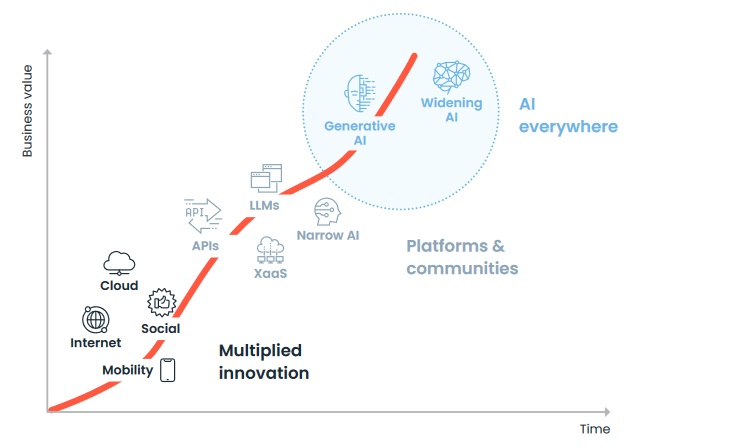
Generative AI represents more than just a technological advancement; it's a transformative shift in how businesses operate. Companies are beginning to tap into its ability to enhance processes, innovate products and improve customer experiences. According to a new IDC InfoBrief sponsored by Endava, 60% of CEOs globally highlight deploying AI, including generative AI, as their top modernization priority to support digital business ambitions over the next two years ...
Technology leaders will invest in AI-driven customer experience (CX) strategies in the year ahead as they build more dynamic, relevant and meaningful connections with their target audiences ... As AI shifts the CX paradigm from reactive to proactive, tech leaders and their teams will embrace these five AI-driven strategies that will improve customer support and cybersecurity while providing smoother, more reliable service offerings ...