While there is high enthusiasm for AI — with 92% of those surveyed in the manufacturing industry confirming AI is a top C-Suite priority and 92% agree it provides a competitive advantage — only 32% of manufacturers are fully prepared to implement AI projects now, 5% lower than the overall industry average, according to Manufacturing sector results of the Riverbed Global AI & Digital Experience Survey ...

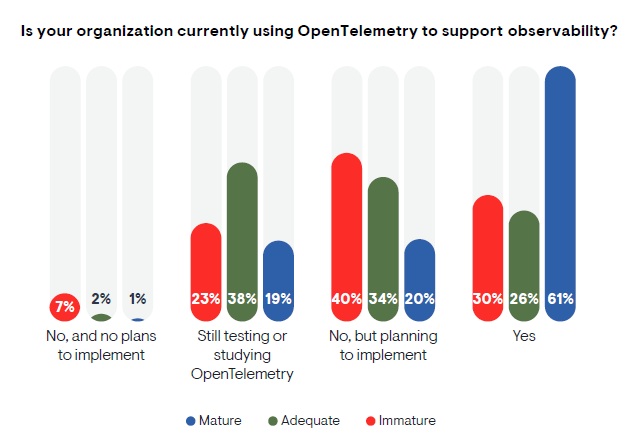
OpenTelemetry enjoys a positive perception, with half of respondents considering OpenTelemetry mature enough for implementation today, and another 31% considering it moderately mature and useful, according to a new EMA report, Taking Observability to the Next Level: OpenTelemetry's Emerging Role in IT Performance and Reliability ... and almost everyone surveyed (98.7%) expresses support for where OpenTelemetry is heading ...
If you've been in the tech space for a while, you may be experiencing some deja vu. Though often compared to the adoption and proliferation of the internet, Generative AI (GenAI) is following in the footsteps of cloud computing ...
Lose your data and the best case scenario is, well, you know the word — but at worst, it is game over. And so World Backup Day has traditionally carried a very simple yet powerful message for businesses: Backup. Your. Data ...

A large majority (79%) believe the current service desk model will be unrecognizable within three years, and nearly as many (77%) say new technologies will render it redundant by 2027, according to The Death (and Rebirth) of the Service Desk, a report from Nexthink ...
Open source dominance continues in observability, according to the Observability Survey from Grafana Labs. A remarkable 75% of respondents are now using open source licensing for observability, with 70% reporting that their organizations use both Prometheus and OpenTelemetry in some capacity. Half of all organizations increased their investments in both technologies for the second year in a row ...
Significant improvements in operational resilience, more effective use of automation and faster time to market are driving optimism about IT spending in 2025, with a majority of leaders expecting their budgets to increase year-over-year, according to the 2025 State of Digital Operations Report from PagerDuty ...

Are they simply number crunchers confined to back-office support, or are they the strategic influencers shaping the future of your enterprise? The reality is that data analysts are far more the latter. In fact, 94% of analysts agree their role is pivotal to making high-level business decisions, proving that they are becoming indispensable partners in shaping strategy ...
Today's enterprises exist in rapidly growing, complex IT landscapes that can inadvertently create silos and lead to the accumulation of disparate tools. To successfully manage such growth, these organizations must realize the requisite shift in corporate culture and workflow management needed to build trust in new technologies. This is particularly true in cases where enterprises are turning to automation and autonomic IT to offload the burden from IT professionals. This interplay between technology and culture is crucial in guiding teams using AIOps and observability solutions to proactively manage operations and transition toward a machine-driven IT ecosystem ...
Gartner identified the top data and analytics (D&A) trends for 2025 that are driving the emergence of a wide range of challenges, including organizational and human issues ...
Traditional network monitoring, while valuable, often falls short in providing the context needed to truly understand network behavior. This is where observability shines. In this blog, we'll compare and contrast traditional network monitoring and observability — highlighting the benefits of this evolving approach ...
A recent Rocket Software and Foundry study found that just 28% of organizations fully leverage their mainframe data, a concerning statistic given its critical role in powering AI models, predictive analytics, and informed decision-making ...
What kind of ROI is your organization seeing on its technology investments? If your answer is "it's complicated," you're not alone. According to a recent study conducted by Apptio ... there is a disconnect between enterprise technology spending and organizations' ability to measure the results ...
In today’s data and AI driven world, enterprises across industries are utilizing AI to invent new business models, reimagine business and achieve efficiency in operations. However, enterprises may face challenges like flawed or biased AI decisions, sensitive data breaches and rising regulatory risks ...
In MEAN TIME TO INSIGHT Episode 12, Shamus McGillicuddy, VP of Research, Network Infrastructure and Operations, at EMA discusses purchasing new network observability solutions....