One of the key performance indicators for IT Ops is MTTR (Mean-Time-To-Resolution). MTTR essentially measures the length of your incident management lifecycle: from detection; through assignment, triage and investigation; to remediation and resolution. IT Ops teams strive to shorten their incident management lifecycle and lower their MTTR, to meet their SLAs and maintain healthy infrastructures and services. But that's often easier said than done, with incident triage being a key factor in that challenge.

Why Incident Triage is Critical for Lowering MTTR
One of the main side effects of today's increasingly complex, hybrid and constantly changing IT environments is the proliferation of disparate ops teams, tools, apps and environments. This in turn leads to high volumes of IT incidents that lack full business context.
As a result, it has become increasingly difficult for first incident responders to triage incoming incidents: Without the ability to understand the incidents' severity based on their business priorities and their impact on services or customers, their routing information, and more — IT Ops teams often waste valuable time determining what to do next, and in doing so, lengthen the incident management lifecycle.
In essence, incident triage has grown to play a key role in determining MTTR in modern, hybrid environments.
Manual Incident Triage Can Be Painful
Because different applications and services have different impacts on customers, availability and revenue, when several incidents occur at the same time it is imperative for incident responders in IT Ops and NOC teams to identify the priority in which these incidents need to be dealt with, and how best to deal with each of them. For teams to be able to rapidly perform this triage, they need access to critical business context and business metrics:
■ The business severity of each incident
■ The services each of them impact
■ Whom to route them to
■ In which priority to do so
■ And other context based on the organization's relevant processes and services.
Without easy access to this information, the teams waste precious time tracking down relevant spreadsheets, runbooks, and other sources of tribal knowledge, as well as manually calculating the business metrics needed to help them understand the incidents' implications.
The more time that is spent on these manual steps, the longer the incident triage lasts.
And the longer that takes, the higher the probability that SLAs are violated, MTTR is kept high, and costs associated with high MTTR rapidly increase.
The solution? Automating incident triage.
Automating Incident Triage
Incident triage can be automated by following several key guidelines:
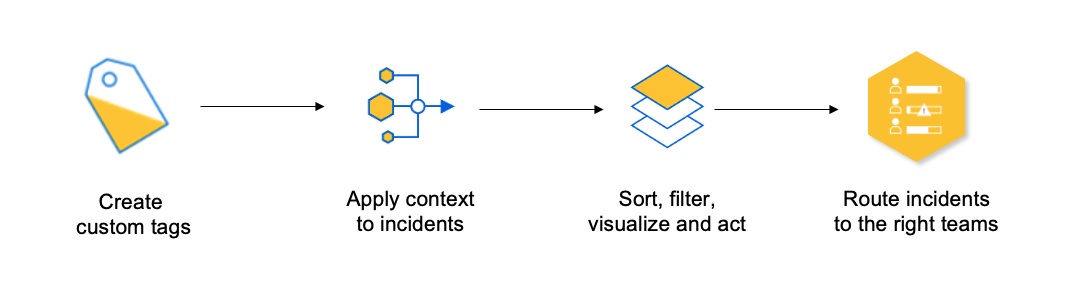
■ The first step is to allow relevant business context information to reside on the incident level, rather than on the alert level. This can be done by creating custom tags for incidents that can hold this information and be acted upon (filtering, sorting etc).
■ The next step is to create simple yet robust formulas that allow operators to automatically calculate the values and metrics held by these tags. For example — calculate the SLA values in an SLA tag, based on the customer and the service to which the incident is referring. By automatically calculating the values and attaching them to the incident by using tags, the need to search for this information manually within tribal knowledge sources is eliminated, as is the need to calculate the values manually when the incident happens.
■ Now — provide filtering and sorting capabilities based on these tag values, and facilitate effective visualization of these tags alongside the incidents, so teams can easily make decisions and act on the incidents based on what they are seeing.
■ Finally — allow routing automation based on the tag values, so large volumes of incidents can be dealt with by relevant teams or automated resolution processes.
The Short and Long Term Advantages of Automating Incident Triage
The first advantage of incident triage automation is self-evident in all that was just discussed, mainly a shorter incident lifecycle — leading to improved performance and availability for apps and services. It's simple — lower MTTR equals better service.
But let's not forget two additional, substantial gains.
First — improved NOC productivity. By providing the above-mentioned capabilities, a substantial part of the incident lifecycle becomes simpler, and teams can collaborate better — lowering stress and effort across the board. Over time, the collected information can also be used for ongoing improvements in tools and processes.
And second — reclaimed FTE hours, an often “hidden” cost-reducer and revenue-generator. By reclaiming thousands of operational “fire-fighting” man-hours and utilizing them to improve and develop new services, enterprises not only reduce costs but also accelerate their business.
The Latest
Industry experts offer predictions on how NetOps, Network Performance Management, Network Observability and related technologies will evolve and impact business in 2025 ...
In APMdigest's 2025 Predictions Series, industry experts offer predictions on how Observability and related technologies will evolve and impact business in 2025. Part 6 covers cloud, the edge and IT outages ...
In APMdigest's 2025 Predictions Series, industry experts offer predictions on how Observability and related technologies will evolve and impact business in 2025. Part 5 covers user experience, Digital Experience Management (DEM) and the hybrid workforce ...
In APMdigest's 2025 Predictions Series, industry experts offer predictions on how Observability and related technologies will evolve and impact business in 2025. Part 4 covers logs and Observability data ...
In APMdigest's 2025 Predictions Series, industry experts offer predictions on how Observability and related technologies will evolve and impact business in 2025. Part 3 covers OpenTelemetry, DevOps and more ...
In APMdigest's 2025 Predictions Series, industry experts offer predictions on how Observability and related technologies will evolve and impact business in 2025. Part 2 covers AI's impact on Observability, including AI Observability, AI-Powered Observability and AIOps ...
The Holiday Season means it is time for APMdigest's annual list of predictions, covering IT performance topics. Industry experts — from analysts and consultants to the top vendors — offer thoughtful, insightful, and often controversial predictions on how Observability, APM, AIOps and related technologies will evolve and impact business in 2025 ...
Technology leaders will invest in AI-driven customer experience (CX) strategies in the year ahead as they build more dynamic, relevant and meaningful connections with their target audiences ... As AI shifts the CX paradigm from reactive to proactive, tech leaders and their teams will embrace these five AI-driven strategies that will improve customer support and cybersecurity while providing smoother, more reliable service offerings ...
We're at a critical inflection point in the data landscape. In our recent survey of executive leaders in the data space — The State of Data Observability in 2024 — we found that while 92% of organizations now consider data reliability core to their strategy, most still struggle with fundamental visibility challenges ...








