Let me explain.
It's a time-honored tradition to drag ticketing platforms through the mud. There's no easier blog to write than the one that bags on an entire industry for pricing, fees, and a monopoly on live events. The president is even getting in on it. True or not, that's not my purpose here.
I want to talk about software testing.
Look, no matter how you think about online ticket brokers, what they're trying to do is really hard. I'm not talking about their business, events management, artist contracts or any of that. I'm talking about the logistics of creating a software platform with ultra-high-volume ticket sales that come in dramatic bursts.
The event covered here occurred at the intersection of three different kinds of testing: performance, security, and chaos. I've never worked or consulted for a company where these were done by the same team — folklore has it that the teams doing this testing generally don't even work directly with the people responsible for the areas they're testing!
Each of these is a career path unto itself. Many books have been written, and much venture capital has spilled into companies centered around them.
Why don't they talk to each other?
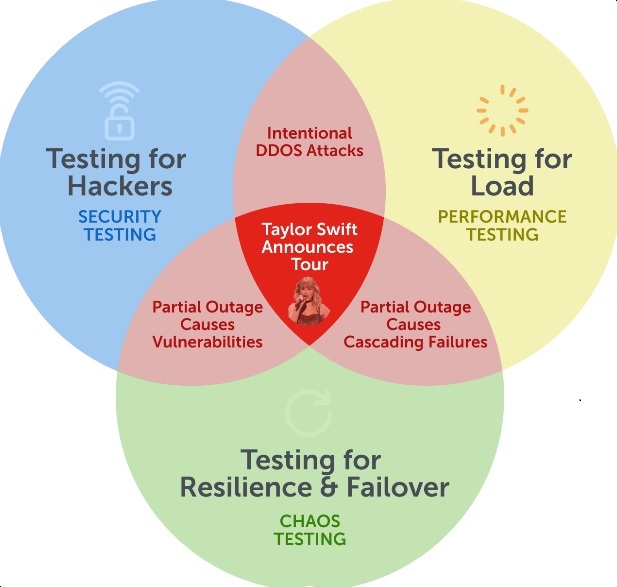
It's important to understand the convergence of these disciplines, lest you live in perpetual fear of the Swifties.
What Happened
On November 1, Taylor Swift announced the Eras Tour, her 6th world tour, commemorating the release of her 10th studio album. Presales tickets popped up on a major ticketing site, which promptly groaned, creaked, and fell over. Fearless Swifties hammered the site without mercy, and as the small Utah theme park called "Evermore" found out, that can be a problem.
Unlike the decidedly low-tech method available to me when I bought Van Halen tickets from the grocery store in 1989, the whole world is now standing in the same virtual queue, and even the most durable cloud architecture can't handle this level of deluge.
People will abandon a brand in a flash when they don't have a good experience, so when they don't have a choice about where they get their tickets from, they turn to the best tools they have (TikTok, Twitter, and Instagram) for their outrage.
We Are Measured In Uptime
Your reputation is measured in 9s. If you have "3 9s of reliability," your site is up 99.9% of the time. In the early 2010s, this was the gold standard, even though it meant you could only be in the red for 8h 46m in a year (about 10 minutes a week). This was the early days of cloud computing, distributed architecture, regional failover, and SRE.
Now, 4- and 5-9s is the standard — you don't even have seconds before Reddit sees hundreds of angry posts. The average Taylor Swift lover doesn't care if you have 99.999% up-time (5:16 of outage per year). The only time Swifties are even looking at your ticketing site is during that 5 minutes of outage!

That is a very powerful, very loud, very large group of people to be angry with you all at once. This isn't just ticketing platforms — it extends to game releases, the newest iPhone, Marvel movies, mortgage interest rate changes, bank runs, toilet paper hoarding and many, many more.
Performance Testing
Any time you have a large number of requests sent to a service with finite resources, you risk it being overrun.
Not just API-based performance testing, but also functional performance testing, preferably with multiple browsers and mobile devices, done from multiple data centers around the US (or around the world) to ensure you can cover traffic with different latencies, different geographic origin, etc.
Most performance testing seems to be done from internal infrastructure, and this is where I would urge you to rely on cloud providers to give you the diversity of region, machine type, and device. It also requires deep monitoring and error reporting to be embedded into production systems.
Security Testing
Once hackers get wind that a site is down for one reason, they can look for open pathways to attack other parts of the system. They can even start to anticipate this when they know that particular businesses are regularly brought down by large traffic volumes!
And this isn't just penetration and hacker testing, but also DDOS testing, and making sure your systems are resilient to more than code attacks. When a microservice is brought down by an attack, it can be like an open pipe — one that runs in both directions. You need to make sure a partial system outage doesn't render the rest of your system open to unintended uses of your APIs.
Chaos Testing
This issue is related to chaos testing because, well, it's right there in the word: a situation arises where not only do you not control, but also you don't even know what's going on in various parts of the system.
Chaos testing isn't as widespread as it should be. Companies that do have dedicated teams and infrastructure enjoy a level of confidence in their system that inspires envy in others, but they also tend to work in isolation. If they have their own environment, segregated from the dev/test environments, it's often not known how their work can apply to other teams (unless they uncover something huge). They need to work with Security and Performance testing teams to make sure that systems can expect the unexpected, and that failover systems work as designed.
Conclusion
This issue is related to all three of these disciplines because you simply can't cover this with a single methodology. People tend to think of QA as one monolithic blob of overlapping skill sets, but there are significant differences between the craft, the threats, and the risk profile covered by each. I can't give you the recipe for how to fix it, except to say that it's going to depend on your particular situation, and the human element of how your teams communicate. Risk modeling for this needs to be hyper-collaborative.
This requires strong executive leadership, as well as a good understanding of the blast radius of these failures. It's not only very difficult, but until recently I'd argue that it wasn't possible.
My advice to all these teams: get into a room together and speak, now, unless you want these headlines to keep waking you up on random midnights!
Thank goodness BTS is on a break — now you have some time to prepare; though I hear Harry Styles has a lot going on …
The Latest
The use of hybrid multicloud models is forecasted to double over the next one to three years as IT decision makers are facing new pressures to modernize IT infrastructures because of drivers like AI, security, and sustainability, according to the Enterprise Cloud Index (ECI) report from Nutanix ...
Over the last 20 years Digital Employee Experience has become a necessity for companies committed to digital transformation and improving IT experiences. In fact, by 2025, more than 50% of IT organizations will use digital employee experience to prioritize and measure digital initiative success ...
While most companies are now deploying cloud-based technologies, the 2024 Secure Cloud Networking Field Report from Aviatrix found that there is a silent struggle to maximize value from those investments. Many of the challenges organizations have faced over the past several years have evolved, but continue today ...
In our latest research, Cisco's The App Attention Index 2023: Beware the Application Generation, 62% of consumers report their expectations for digital experiences are far higher than they were two years ago, and 64% state they are less forgiving of poor digital services than they were just 12 months ago ...
In MEAN TIME TO INSIGHT Episode 5, Shamus McGillicuddy, VP of Research, Network Infrastructure and Operations, at EMA discusses the network source of truth ...
A vast majority (89%) of organizations have rapidly expanded their technology in the past few years and three quarters (76%) say it's brought with it increased "chaos" that they have to manage, according to Situation Report 2024: Managing Technology Chaos from Software AG ...
In 2024 the number one challenge facing IT teams is a lack of skilled workers, and many are turning to automation as an answer, according to IT Trends: 2024 Industry Report ...
Organizations are continuing to embrace multicloud environments and cloud-native architectures to enable rapid transformation and deliver secure innovation. However, despite the speed, scale, and agility enabled by these modern cloud ecosystems, organizations are struggling to manage the explosion of data they create, according to The state of observability 2024: Overcoming complexity through AI-driven analytics and automation strategies, a report from Dynatrace ...
Organizations recognize the value of observability, but only 10% of them are actually practicing full observability of their applications and infrastructure. This is among the key findings from the recently completed Logz.io 2024 Observability Pulse Survey and Report ...
Businesses must adopt a comprehensive Internet Performance Monitoring (IPM) strategy, says Enterprise Management Associates (EMA), a leading IT analyst research firm. This strategy is crucial to bridge the significant observability gap within today's complex IT infrastructures. The recommendation is particularly timely, given that 99% of enterprises are expanding their use of the Internet as a primary connectivity conduit while facing challenges due to the inefficiency of multiple, disjointed monitoring tools, according to Modern Enterprises Must Boost Observability with Internet Performance Monitoring, a new report from EMA and Catchpoint ...



